Algebra is the offer made by the devil to the mathematician. The devil says: “I will give you this powerful machine, it will answer any question you like. All you need to do is give me your soul: give up geometry and you will have this marvelous machine. — Michael Atiyah
Back in the day when dinosaurs still roamed Palo Alto and I was a clueless Stanford junior undergrad, I tried and failed many times to understand Gröbner bases. Now I have to implement Gröbner bases for my research, after a Saturday’s suffering, I finally seem to understand what’s going on with Gröbner bases from the wonderful paper [1] What can be computed in algebraic geometry?. This note summarises my learning so far. In retrospect, I hope someone taught me this when I took my first scheme-based algebraic geometry class as an example of the subtlety of algebraic structures compatible with algebraic varieties.
Gröbner Bases
First recall Buchberger’s algorithm which finds a basis for an ideal  of a polynomial ring
of a polynomial ring  proceeds as follows (pseudo-code generated by Claude based on the Wikipedia page).
proceeds as follows (pseudo-code generated by Claude based on the Wikipedia page).
Input A set of polynomials  that generates
that generates
Output A Gröbner basis  for
for

- For every
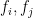 in , denote by
in , denote by 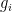 the leading term of
the leading term of  with respect to the given monomial ordering, and by
with respect to the given monomial ordering, and by  the least common multiple of and
the least common multiple of and 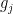 .
.
- Choose two polynomials in and let
 (Note that the leading terms here will cancel by construction).
(Note that the leading terms here will cancel by construction).
- Reduce
 with the multivariate division algorithm relative to the set until the result is not further reducible. If the result is non-zero, add it to .
with the multivariate division algorithm relative to the set until the result is not further reducible. If the result is non-zero, add it to .
- Repeat steps 2–4 until all possible pairs are considered, including those involving the new polynomials added in step 4.
- Output .
When I first learnt about this, it seemed to me extremely unclear what exactly is going on. Why do we choose a monomial ordering? How does the choice of a different monomial ordering affect the runtime? The geometric insight in [1] is to relate the monomial ordering to a 1-parameter family of automorphism of the projective space wherein the variety defined by the set of polynomials embeds.
In particular, let  be the algebraic variety defined by (take homogenization) in some projective scheme
be the algebraic variety defined by (take homogenization) in some projective scheme  , consider a one-parameter subgroup
, consider a one-parameter subgroup  of the diagonal form
of the diagonal form
 where each
where each  induces an automorphism of where we identify the image of as
induces an automorphism of where we identify the image of as  . Let
. Let  be a monomial in the homogeneous coordinate ring of . Then the automorphism maps a homogenous polynomial
be a monomial in the homogeneous coordinate ring of . Then the automorphism maps a homogenous polynomial  to
to  .
.
From here, one may take projective limits of  and in the projective spaces and ponder what happens at
and in the projective spaces and ponder what happens at  . The upshot is that with a particular choice of the one-parameter automorphism groups, we can recover exactly the monomial ordering (exercise: recover the lexicographic and reverse lexicographic ordering this way; the reverse lexicographic order described in [1] is actually the graded lexicographic order, but they coincide here since we consider homogeneous coordinates) as the projective limit of
. The upshot is that with a particular choice of the one-parameter automorphism groups, we can recover exactly the monomial ordering (exercise: recover the lexicographic and reverse lexicographic ordering this way; the reverse lexicographic order described in [1] is actually the graded lexicographic order, but they coincide here since we consider homogeneous coordinates) as the projective limit of  for
for  away from
away from  .
.
Back to the question about what happens to  as approaches , the “right” perspective is to define a
as approaches , the “right” perspective is to define a ![{\mathbb{P}^n[t]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BP%7D%5En%5Bt%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) -scheme
-scheme 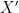 whose fiber at recovers . An obvious attempt is to define to be generated by each
whose fiber at recovers . An obvious attempt is to define to be generated by each  as the quotient of
as the quotient of  divided by the largest power of in its monomials, which would recover at fibers away from . However, at , the situation is not nice as the projection from is not necessarily flat (or equivalently the syzygies upstairs do not generate the ones downstairs). To make it flat, we lift syzygies upstairs, which amounts to adding “-torsion” points to the coordinate rings, which recovers exactly the “multivariate division” part of Buchberger’s algorithm! Therefore the Gröbner bases in some sense define a flat family of varieties whose fiber at general position recovers the original variety .
divided by the largest power of in its monomials, which would recover at fibers away from . However, at , the situation is not nice as the projection from is not necessarily flat (or equivalently the syzygies upstairs do not generate the ones downstairs). To make it flat, we lift syzygies upstairs, which amounts to adding “-torsion” points to the coordinate rings, which recovers exactly the “multivariate division” part of Buchberger’s algorithm! Therefore the Gröbner bases in some sense define a flat family of varieties whose fiber at general position recovers the original variety .
Connections to Regularity
It turns out Gröbner bases relate to Hilbert functions and its computational complexity relates to Castelnuovo-Mumford regularity (also can be used to construct Hilbert schemes). I strongly recommend working through the example in [1] to gain intuition. One particular nice thing is that reducing by lexicographic order or reversed lexicographic order is related to projection of the orignal variety to some subspaces ([1] discusses really cool connections to flag varieties in birational geoemtry). The upshot is that lexicographic order reduction corresponds to the projection  where is viewed as the Thom space of the tautological bundle over
where is viewed as the Thom space of the tautological bundle over  and reverse lexicographic order reduction corresponds to projection from the point at infinity. This intuitively explains why in practice reverse lexicographic order reduction works better, as the relevant projection maps are simpler – which is pretty cool as the hidden geometry is not obvious at all if one only thinks about the ordering.
and reverse lexicographic order reduction corresponds to projection from the point at infinity. This intuitively explains why in practice reverse lexicographic order reduction works better, as the relevant projection maps are simpler – which is pretty cool as the hidden geometry is not obvious at all if one only thinks about the ordering.
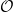
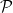



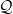







 and
and  Loop
Loop  down to
down to  Set
Set  If
If  Set
Set  Set
Set  End If
End
End If
End  Loop
Return the value
Loop
Return the value 